Sep 9, 2014
Consensual hells: Geopolitics for individuals
My third guest post at ribbonfarm.com.
* *
My third guest post at ribbonfarm.com.
My second guest post has just been published over at ribbonfarm.com, on the subject of building capture-resistant organizations. Tl;dr - constrain individual discretion at the top, and empower it on the fringes. But the direct ways to do that won't work. What will? Read on →
I've just published the first of a series of guests posts over at ribbonfarm.com. Check it out.
If you're a programmer this has happened to you. You've built or known a
project that starts out with a well-defined purpose and a straightforward
mapping from purpose to structure in a few sub-systems.
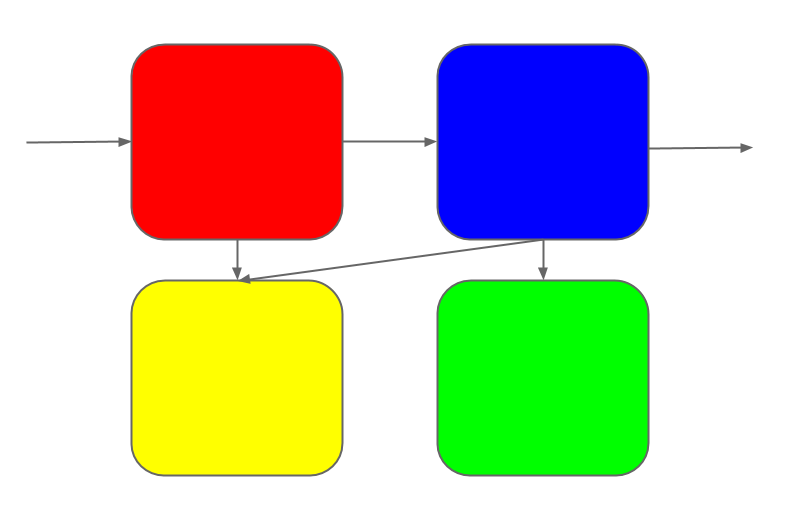
But it can't stand still; changes continue to roll in.
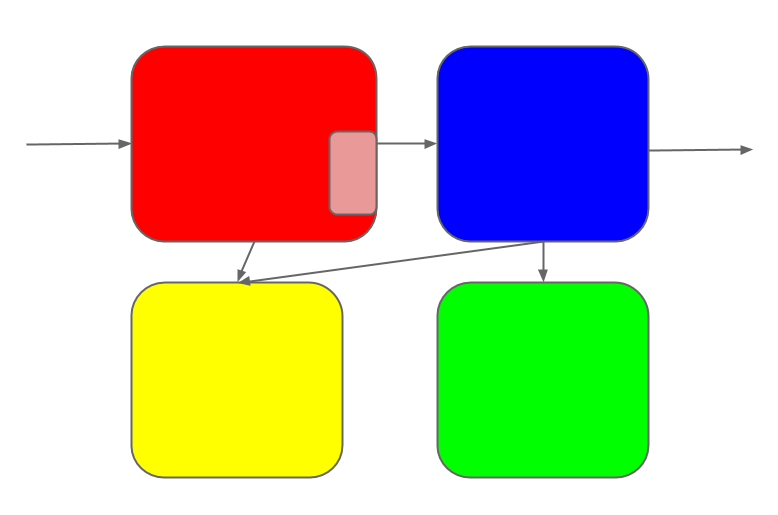
Some of the changes touch multiple sub-systems.
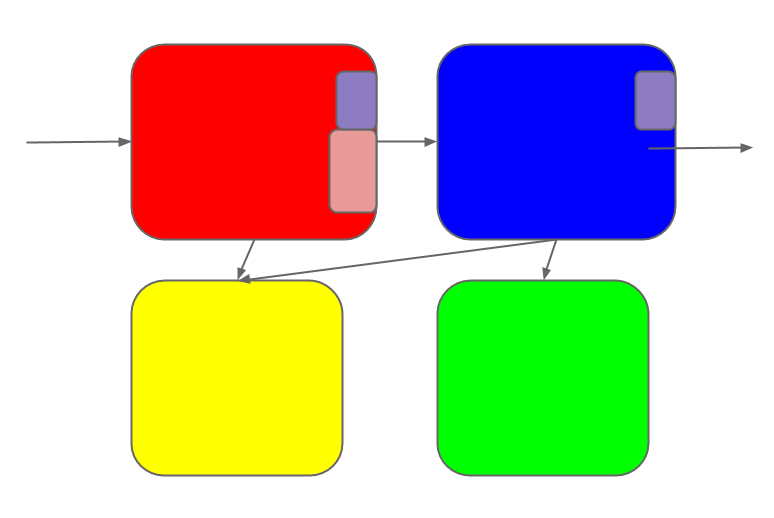
Each change is coherent in the mind of its maker. But once it's made, it
diffuses into the system as a whole.
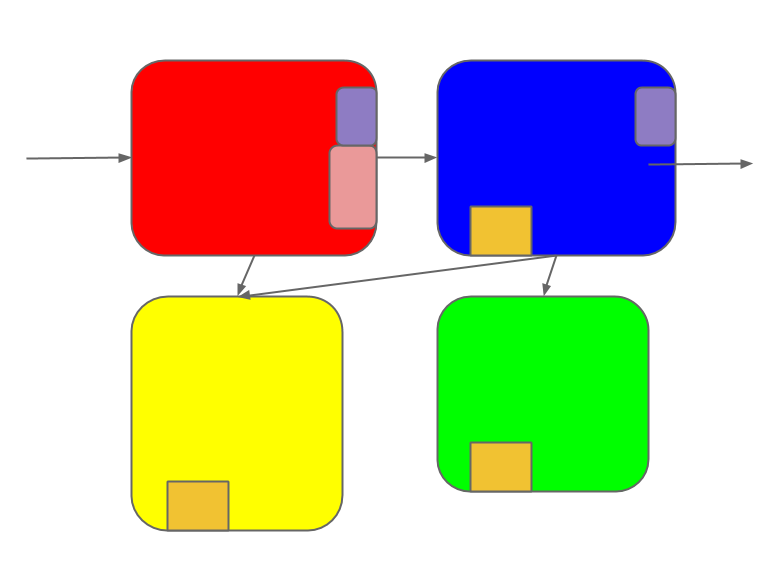
Soon the once-elegant design has turned into a patchwork-quilt of changes.
Requirements shift, parts get repurposed. Connections proliferate.
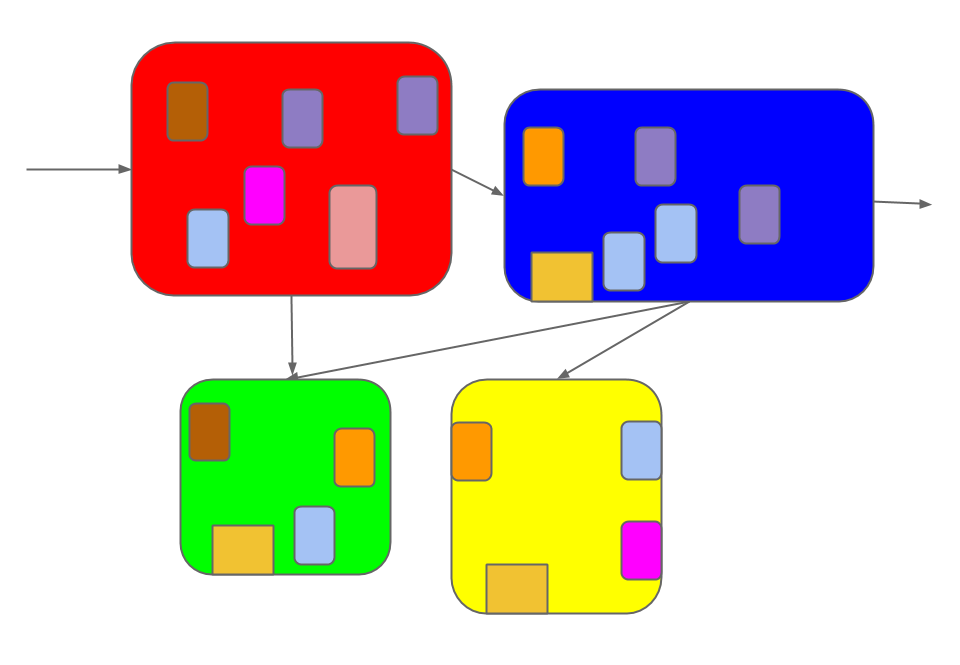
Veterans who watched this evolution can keep it mostly straight in their
heads. But newcomers see only the patchwork quilt. They can't tell where one
feature begins and another ends.
What if features could stay separate as they're added, so that newcomers could
see a cleaned-up history of the
process?
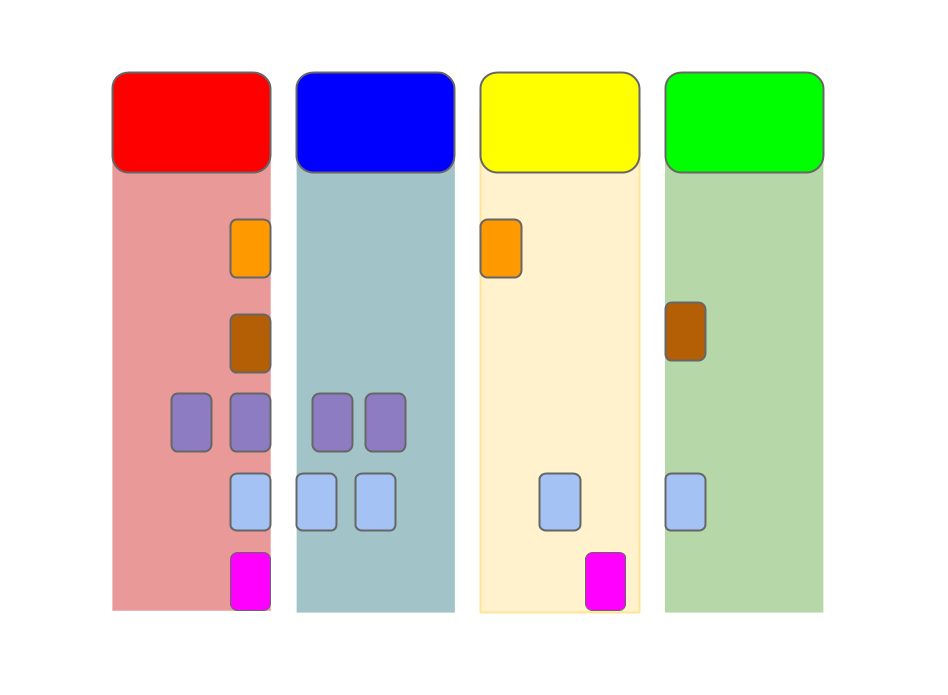
Solution Read more →
(I still haven't found a way to describe it to non-programmers.)
Wart is an experimental, dynamic, batshit-liberal language designed to eventually be used by small teams of hobbyists writing potentially long-lived software. The primary goal is to be easy for anyone to understand and modify. This goal goes for both code written in Wart, and the code implementing Wart.
$ git clone http://github.com/akkartik/wart $ git checkout c73dcd8d6 # state when I wrote this article $ cd wart $ ./wart # you'll need gcc and unix ready! type in an expression, then hit enter twice. ctrl-d exits. 1+1 ⇒ 2
We programmers love to talk about the value of readability in software. But all our rhetoric, even if it were practiced with diligence, suffers from a giant blind spot.
Exhibit A
Here's Douglas Crockford on programming style. For the first half he explains why readability is important: because our brains do far more subconsciously than we tend to realize. The anecdotes are interesting and the presentation is engaging, but the premise is basically preaching to the choir. Of course I want my code to be readable. Sensei, show me how!
But when he gets to ‘how’, here is what we get: good names, comments and consistent indentation. Wait, what?! After all that discussion about how complex programs are, and how hard to understand, do we really expect to make a dent on global complexity with a few blunt, local rules? Does something not seem off?
Exhibit B Read more →
There's a combinatorial explosion at the heart of writing tests: the more coarse-grained the test, the more possible code paths to test, and the harder it gets to cover every corner case. In response, conventional wisdom is to test behavior at as fine a granularity as possible. The customary divide between 'unit' and 'integration' tests exists for this reason. Integration tests operate on the external interface to a program, while unit tests directly invoke different sub-components.
But such fine-grained tests have a limitation: they make it harder to move function boundaries around, whether it's splitting a helper out of its original call-site, or coalescing a helper function into its caller. Such transformations quickly outgrow the build/refactor partition that is at the heart of modern test-based development; you end up either creating functions without tests, or throwing away tests for functions that don't exist anymore, or manually stitching tests to a new call-site. All these operations are error-prone and stress-inducing. Does this function need to be test-driven from scratch? Am I losing something valuable in those obsolete tests? In practice, the emphasis on alternating phases of building (writing tests) and refactoring (holding tests unchanged) causes certain kinds of global reorganization to never happen. In the face of gradually shifting requirements and emphasis, codebases sink deeper and deeper into a locally optimum architecture that often has more to do with historical reasons than thoughtful design.
I've been experimenting with a new approach to keep the organization of code more fluid, and to keep tests from ossifying it. Rather than pass in specific inputs and make assertions on the outputs, I modify code to judiciously print to a trace and make assertions on the trace at the end of a run. As a result, tests no longer need call fine-grained helpers directly. Read more →
When I said that libraries suck, I wasn't being precise.1 Libraries do lots of things well. They allow programmers to quickly prototype new ideas. They allow names to have multiple meanings based on context. They speed up incremental recompiles, they allow programs on a system to share code pages in RAM. Back in the desktop era, they were even units of commerce. All this is good.
What's not good is the expectation they all-too-frequently set with their users: go ahead, use me in production without understanding me. This expectation has ill-effects for both producers and consumers. Authors of libraries prematurely freeze their interfaces in a futile effort to spare their consumers inconvenience. Consumers of libraries have gotten trained to think that they can outsource parts of their craft to others, and that waiting for 'upstream' to fill some gap is better than hacking a solution yourself and risking a fork. Both of these are bad ideas. Read more →
That's my immediate reaction watching these programmers argue about what color their comments should be when reading code. It seems those who write sparse comments want them to pop out of the screen, and those who comment more heavily like to provide a background hum of human commentary that's useful to read in certain contexts and otherwise easy to filter out.
Now that I think about it, this matches my experience. I've experienced good codebases commented both sparsely and heavily. The longer I spend with a sparsely-commented codebase, the more I cling to the comments it does have. They act as landmarks, concise reminders of invariants. However, as I grow familiar with a heavily-commented codebase I tend to skip past the comments. Code is non-linear and can be read in lots of ways, with lots of different questions in mind. Inevitably, narrative comments only answer some of those questions and are a drag the rest of the time.
I'm reminded of one of Lincoln's famous quotes, a fore-shadowing of the CAP theorem. Comments can be either detailed or salient, never both.
Comments are versatile. Perhaps we need two kinds of comments that can be colored differently. Are there still other uses for them? Read more →
Here's why, in a sentence: they promise to be abstractions, but they end up becoming services. An abstraction frees you from thinking about its internals every time you use it. A service allows you to never learn its internals. A service is not an abstraction. It isn't 'abstracting' away the details. Somebody else is thinking about the details so you can remain ignorant.
Programmers manage abstraction boundaries, that's our stock in trade. Managing them requires bouncing around on both sides of them. If you restrict yourself to one side of an abstraction, you're limiting your growth as a programmer.1 You're chopping off your strength and potential, one lock of hair at a time, and sacrificing it on the altar of convenience.
A library you're ignorant of is a risk you're exposed to, a now-quiet frontier that may suddenly face assault from some bug when you're on a deadline and can least afford the distraction. Better to take a day or week now, when things are quiet, to save that hour of life-shortening stress when it really matters. Read more →