If you're a programmer this has happened to you. You've built or known a
project that starts out with a well-defined purpose and a straightforward
mapping from purpose to structure in a few sub-systems.
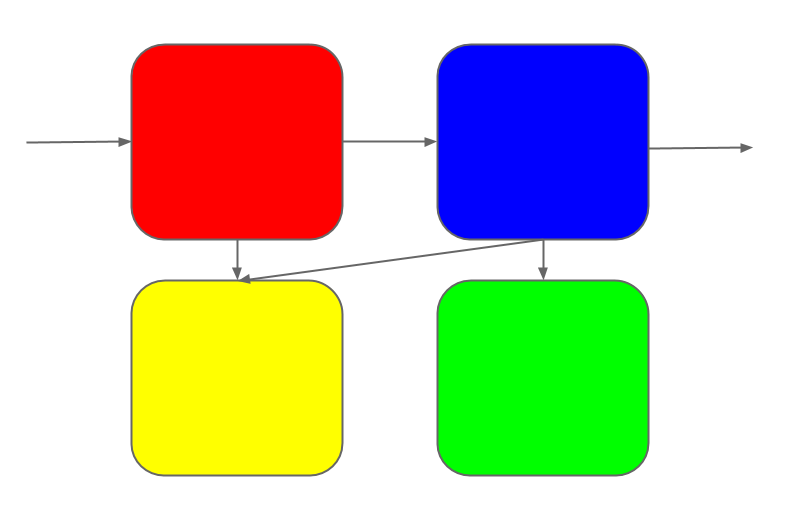
But it can't stand still; changes continue to roll in.
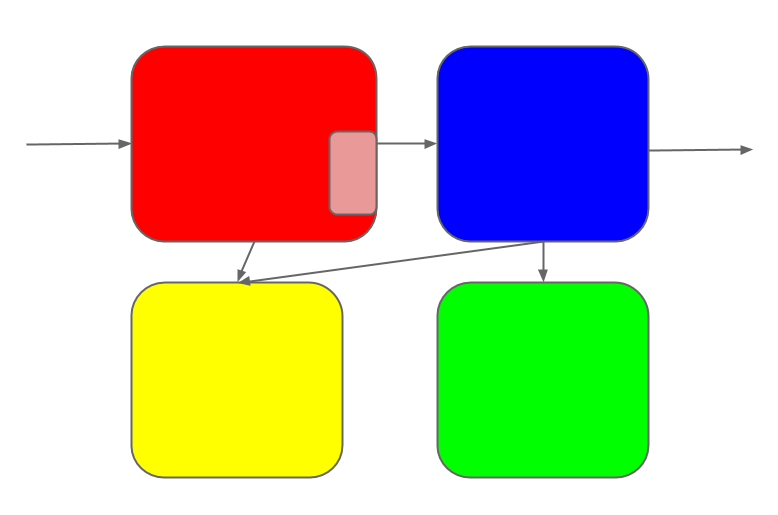
Some of the changes touch multiple sub-systems.
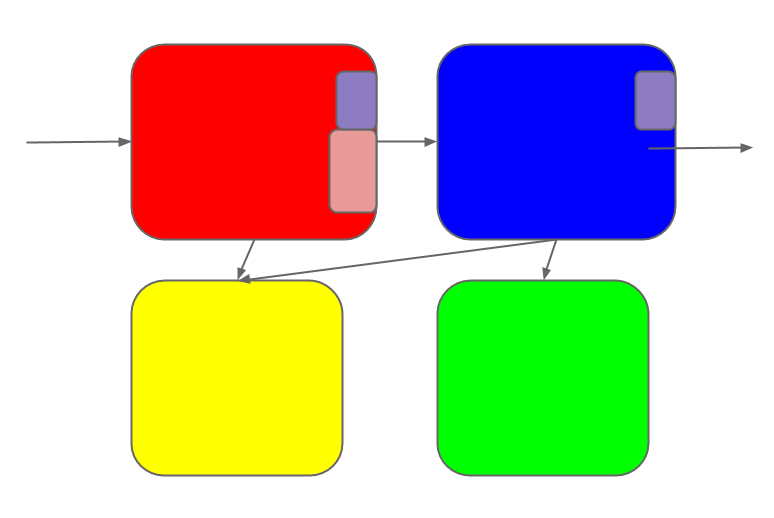
Each change is coherent in the mind of its maker. But once it's made, it
diffuses into the system as a whole.
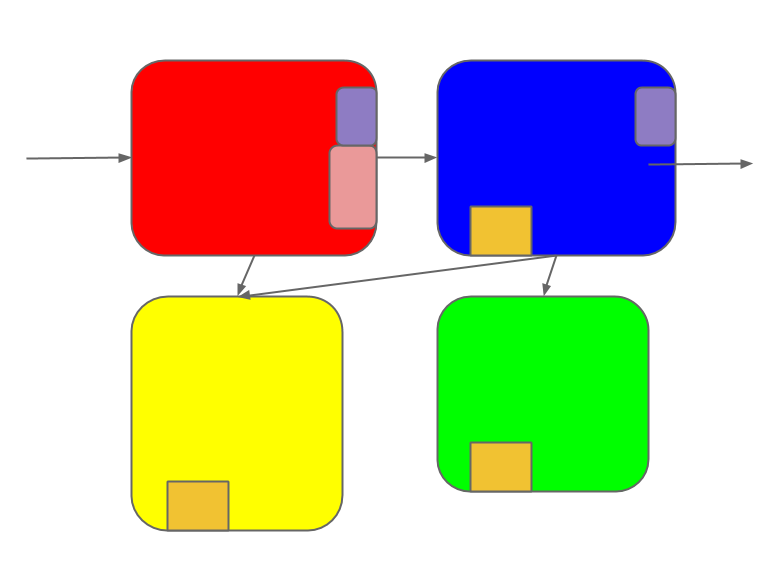
Soon the once-elegant design has turned into a patchwork-quilt of changes.
Requirements shift, parts get repurposed. Connections proliferate.
Veterans who watched this evolution can keep it mostly straight in their
heads. But newcomers see only the patchwork quilt. They can't tell where one
feature begins and another ends.
What if features could stay separate as they're added, so that newcomers could
see a cleaned-up history of the
process?
Solution
Start with a simple program.
// Includes // End Includes // Types // End Types // Globals // End Globals int main(int argc, char* argv[]) { if (argc > 1) { // Commandline Options } return 0; // End Main }
It doesn't do much, it's just a skeleton, but it's a legal program and it builds and runs. Now features can insert code at well-defined points in this program:
:(after "Includes")
#include <list>
#include <string>
The first line above is a directive to find an existing line matching the pattern "Includes", and insert the following lines after it. You can insert arbitrary fragments at arbitrary points, even inside functions:
:(after "Commandline Options")
if (arg == "test")) {
run_tests();
return 0;
}
A simple tool will splice them into the right places:
int main(int argc, char* argv[]) {
if (argc > 1) {
// Commandline Options
if (arg == "test")) {
run_tests();
return 0;
}
}
return 0; // End Main
}
With the help of directives, we can now organize a program as a series of self-contained layers, each containing all the code for a specific feature, regardless of where it needs to go. A feature might be anything from a test harness to a garbage collector. Directives are almost too powerful, but used tastefully they can help decompose programs into self-contained layers.
We aren't just reordering bits here. There's a new constraint that has no counterpart in current programming practice — remove a feature, and everything before it should build and pass its tests:
$ build_and_test_until 000organization $ build_and_test_until 030 $ build_and_test_until 035 ...
Being able to build simpler versions of a program is incredibly useful to newcomers to your project. Playing with simpler versions can help gain fluency with the global architecture of your project. Newcomers can learn and test themselves in stages, starting with the simplest versions and gradually introducing the complexities of peripheral features. Try it for yourself, and tell me what you think!
$ git clone http://github.com/akkartik/wart
$ cd wart/literate
$ make # builds and runs tests; needs gcc and unix
This example is in C, but the idea applies to any language. Free yourself of the constraints imposed by your compiler, and write code for humans to read.
Rationale and history
You might have noticed by now that directives are just a more readable way to express patches. This whole idea is inspired by version control. For some time now I've been telling people about a little hack I use for understanding strange codebases. When I am interested in learning about a new codebase, I skim its git log until I find a tantalizing tag or commit message, like say "version 1". Invariably version 1 is far simpler than the current version. The core use cases haven't yet been swamped by an avalanche of features and exceptions. The skeleton of the architecture is more apparent. So I focus on this snapshot, and learn all I can. Once I understand the skeleton I can play changes forward and watch the codebase fill out in a controlled manner.
But relying on the log for this information is not ideal, because the log is immutable. Often a codebase might have had a major reorg around version 3, so that reading version 1 ends up being misleading, doing more harm than good. My new organization lays out this time axis explicitly in a coherent way, and makes it available to change. The sequence of features is available to be cleaned up as the architecture changes and the codebase evolves.
Codebases have three kinds of changes: bugfixes, new features and reorganizations. In my new organization bugfixes modify a single layer, new features are added in new layers, and reorganizations might make more radical changes, including changing the core skeleton. The hope is that we can now attempt more ambitious reorganizations than traditional refactoring, especially in combination with tracing tests. I'll elaborate on that interaction in the future.
comments
Comments gratefully appreciated. Please send them to me by any method of your choice and I'll include them here.
What does the file structure for the layers look like? Is wart/literate the best place to go t read some code?
Also what do you think is the consequence of using anchors to specific points in the text rather something more oriented towards the structure of the system?
(It was sharp of you to spot the connection to Ruby modules; I actually started Wart wanting to take ruby's notion of open classes to functions in lisp. It's one of my favorite ideas.)
Then I thought of layers this March, and left this idea behind :) Partly because I've always been skeptical of secondary incentives created by tools. The moment you create a tool that makes something easy, programmers will overload it and build software complex enough that it becomes a pain. The path to utopia passes through making them take some responsibility for their tools, IMO. So don't try to maximize intelligibility at a single point in time. If you think about the trajectory, I think, text files are still a win because we don't yet know how to do graphics with a lot less dependencies. Perhaps if I could get on the stack that Alan Kay is building...
Observations:
* this would be a lot easier if performed upon a target language constructed for deep access and rewriting
* similar manipulations apply to non-code artifacts, such as editing of documents, images, 3D models
* updates must be extracted by the programmer's environment, from user actions or resulting diffs in state.
* your directives are likely to be lossy, fragile, e.g. not tracking copy-and-paste actions or decision-making process that went into selecting code.
There is some relationship to issues addressed in my recent manifesto:
https://groups.google.com/forum/#!topic/reactive-demand/gazxhLLXscQ
I'm talking about manipulating a personal environment, not a shared codebase. But I think a similar design is appropriate.
There are the usual tradeoffs here: text files are easier to work with, we can't seem to build a decent GUI with as little code, less code is easier to understand, etc. But I won't belabor the obvious.
I also notice that your idea has some commonality with the boxer paper: http://lambda-the-ultimate.org/node/4695
I was thinking about something similar, but from a different perspective: dependencies. Traditional makefiles manage dependencies as precisely as possible, but that makes code harder to reorganize, which guarantees that nobody will take the trouble to reorg when the org goes stale. So wart punts entirely on dependencies. It just has a simple rule for building and loading everything it finds in a well-defined order. Hence the numeric prefixes, and the emphasis on being able to build everything until a numeric prefix. But layer 655 might not actually need everything from 000 to 654. I'm reluctantly coming around to consider dependencies. How to do them right, so they aren't a pain to maintain? Perhaps they could be automatically inferred and cached somehow? What would a language+platform look like that makes analysis of dependencies trivial? I've been searching for a language model where lexical scopes are trivial to analyze, and it's easy to tell if this variable x is the same binding as that variable x in some other part of the program. If we could solve that elegantly, I feel, deducing dependencies would take very little code.
Anyway, this is all half-baked but I wanted to throw it out there just in case you have suggestions with your extremely wide and different-from-me knowledge.
* which global names are in each file
* which global names depend on other global names
From that point, you could shift to generic Wart code to model a web-of-influence for each patch. (So, just bite the bullet and install some language specific plugins or scripts!)
Caching and snapshots can work very well for incremental processing. I've been getting a lot of mileage from my 'exponential decay of history, improved' - logarithmic list - for things like deciding which snapshots to destroy to make room for new ones, while keeping enough around to quickly rebuild deep history when desired.
I think text files aren't inherently easier to work with. The tools for working with text are prolific and well developed, and that helps make up for the fact that parsing, processing, organizing, navigating, and meaningfully editing text is painful and boring.
In the design I described in the manifesto, 'text files' might be replaced with files of tacit concatenative byte-code that constructs a value. Then, modification of a file would be the same as addending it (implicitly keeping the history) while certain operations might clear the history and rebuild an optimized version of the file. The value in question wouldn't be limited to text, and could represent any object (diagram, geometry, document, graph, etc.).
Boxes. Boxes. Boxes. Hyper-static scope. Boxes. What you describe is trivial in Nulan, because of boxes and hyper-static scope. Boxes can also handle dynamic globals (like Arc/JavaScript) if you insist on that model, though it's not as nice as hyper-static scope, in my opinion.
1) I don't require each layer to be understandable just by reading it in isolation. I'm constantly building my program just up to a certain layer and then reading the generated code, or stepping through it in a debugger. The goal is to support interactivity in the learning process, or active reading if you like.
2) Layers absolutely patch previous layers. That's where they get all their power from. I don't make the distinction between "base program" and "cross-cutting concern". If I did, everything but layer 1 would be cross-cutting concerns. That's near 100% of the program, since I've already shown my layer 1 above: it's an empty skeleton that does nothing.
Layers are more powerful than cross-cutting concerns. They're powerful enough that they become a completely first-class unit of organization. As Alan Kay put it, "take the hardest and most profound thing you need to do, make it great, and then build every easier thing out of it."
3) Since I don't require a "good architecture" before adding a new layer, because my mechanism for inserting code is as just arbitrary patching, and since I constantly make sense of my program by looking at the "joined" version the compiler sees, development is absolutely not blocked on reorganizing.
This doesn't mean there are no drawbacks. I tried to enumerate them in this post, and I'll do a follow-up at some point about lessons learned. But I feel confident that I am making new mistakes and not just repeating AOP's missteps.
However, in practice this leads to an over-engineered mess of factories and
other design patterns, because developers try to support every possible hook.
Worth reading is Martin Sústrik's essay on software as memes subject to natural selection.
Your profile image [1], although it looks a small thumbnail, is a 5.1 MB PNG which takes years to load on slow connections.
[1]: https://cdn.commento.io/api/commenter/photo?commenterHex=472ec38f958dc6b9b3a5498e52b635bf68c4e1645fdb8fd5b364409aa207b659
Programmers familiar with C and Pascal are notorious for their advice to attempt to understand a program by starting at the bottom of the file (e.g. where main usually is) and working backwards. They then habituate themselves to this way of working that it ends up being a sort of missing stairstep not perceived as a deficiency in the programming system they are using. Some who are able to see a bit further end up writing their own idiosyncratic programming system, which they evangelize to the world under the label "literate programming".
Regardless, the point of this article (and something that goes beyond literate programming) is that there shouldn't be a single top. Keeping multiple variants of a program in sync helps readers triangulate on the big picture.
> You can design a program top-down and still put main at the bottom.
Sure, you *can*. What's the benefit? Doing so is counterproductive. Put the stuff people are expected to read first first.
> the point of this article[...] is that there shouldn't be a single top
Are you sure? Maybe your thinking eventually evolved away from what you wrote here, but this article doesn't come off that way. It's rather opposed to that, at least as written.
I totally agree. I just disagree that people are always expected to read main first. As a counter-example, I usually care much more about the data structures.
> Are you sure? Maybe your thinking eventually evolved away from what you wrote here, but this article doesn't come off that way. It's rather opposed to that, at least as written.
Certainly possible, but after a second look I'm not sure what you're seeing. Sure, the example has main up top. But that's just one layer. You can't have main in more than one layer.
Around the same time I wrote this I also wrote http://akkartik.name/post/literate-programming where I said, "There's a pervasive mindset of top-down thinking, of starting from main, whether or not that's easiest to read."
I've certainly used top-down in many of my layers. And I certainly don't advocate for the style of putting main at the bottom just to please a compiler. But it muddies the waters to conflate a design methodology with syntactic ordering. Neophyte readers are liable to think they're doing top-down design just by pushing main up top.
And bottom-up does make sense sometimes. For example, here's this layer (again from around the time of this post) that starts tracking reference counts to cons cells. "Top down" doesn't feel meaningful for this layer.
It sounds like you're still conceptualizing the final form of the program text as if it were a traditional program and wrapping your approach around that. This preoccupation is what I'm referring to. As if there's this quaint approach to communicating how the traditional program evolved, but at the end of the day it's a fiction and the tangled C is still the *real* program.
What I'm saying is forget that.
We should care no more about the tangled version than the average programmer cares about the intermediate assembly that their compiler produces.
To truly prioritize programs-for-humans-first-and-not-machines (the compiler for the target language itself being an abstract machine), then that means we should concern ourselves *only* with the input that gets fed into this programming system, for *that* is the program. (Again, just as contemporary programmers conceive of their C source as constituting their canonical program, and not the assembly that it produces. For all most programmers care, it would be fine for you to write a single-pass compiler to generate their object file(s) directly from the C if that were actually possible. Same thing here—no tangle, just input.)
Basically I'm wondering: What would you add/subtract? Or would you do something totally different?
If we're "programming" our colleagues' mental model with some gentle, thoughtful introduction that we've arranged for the benefit of comprehension, then we should use the same input when explaining to the computer what the program does. Abandon all notions that we're programming C. Forget that C exists, even. It should not be our goal to produce a C program. Let's not say, "here is our program, which is what the compiler and I-the-author operate on when we're doing work, but on the other hand here is a layered narrative to explain how we got to this point". Instead, throw out the former entirely and let there be only the latter. It's what our colleague references, it's what we feed into the compiler, and it's what we deal with ourselves when working on the program.
There should really only be two levels of concern: the concrete, extreme low-level (i.e. the machine) and then the high-level that you actually desire to use for communicating about the behavior and design rationale of the program. Since C isn't bedrock, don't make it an essential detour. (In a way, this is the progression that C++ and Objective-C made. They stopped trying to be glorified preprocessors and began aiming to be languages unto themselves, with varying levels of success at shedding their legacy. What would a language look like if it kept these design goals in mind?) Most programmers pay little attention to the first, lowest level. If there *is* to be an intermediate level (and it's not clear that there should be), then it should demand even less attention than that, not more.
This is my favorite defense of bottom-up programming: http://www.paulgraham.com/progbot.html