Literate programming advocates this: Order your code for others to read,
not for the compiler. Beautifully typeset your code so one can curl up in bed
to read it like a novel. Keep documentation in sync with code. What's not
to like about this vision? I have two beefs with it: the ends are insufficiently
ambitious by focusing on a passive representation; and the means were insufficiently
polished, by over-emphasizing typesetting at the cost of prose quality.
Elaboration, in reverse order:
When I look around at the legacy of literate programming, systems to do so-called semi- or quasi-literate programming dominate. These are systems that focus on generating beautifully typeset documentation without allowing the author to arbitrarily order code. I think this is exactly backwards; codebases are easy to read primarily due to the author's efforts to orchestrate the presentation, and only secondarily by typesetting improvements. As a concrete example, just about every literate program out there begins with cruft like this:1
// Some #includes
or:
-- Don't mind these imports.
I used to think people just didn't understand Knuth's vision. But then I went and looked at his literate programs. Boom, #includes:

The example Pascal program in Knuth's original paper didn't have any imports at all. But when it comes to organizing larger codebases, we've been putting imports thoughtlessly at the top. Right from day one.
Exhibit 2:

“Skip ahead if you are impatient to see the interesting stuff.” Well gee, if only we had, you know, a tool to put the interesting stuff up front.
Exhibit 3:
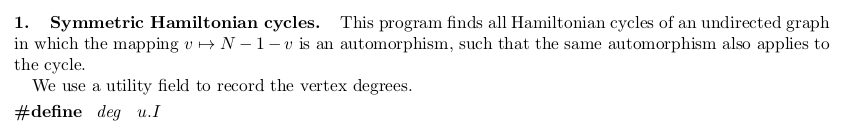
This is the start of the piece. There's a sentence of introduction, and then this:
That's a steep jump across several levels of abstraction. Literally the first line of code shown is a macro to access a field for presumably a struct whose definition — whose very type name — we haven't even seen yet. (The variable name for the struct is also hard-coded in; but I'll stop nit-picking further.)
Exhibit 4: Zoom out just a little bit on the previous example:

Again, there's #includes at the top but I won't belabor that. Let's look at what's in these #includes. "GraphBase data structures" seems kinda relevant to the program. Surely the description should inline and describe the core data structures the program will be using. In the immortal words of Fred Brooks:
Surely a system to optimize order for exposition shouldn't be stymied by code in a different file.
On the whole, people have failed to appreciate the promise of literate programming because the early examples are just not that good, barring the small program in Knuth's original paper. The programs jump across abstraction layers. Problems are ill-motivated. There's a pervasive mindset of top-down thinking, of starting from main, whether or not that's easiest to read. The ability to change order is under-used, perhaps because early literate tools made debugging harder, but mostly I think because of all the emphasis — right from the start — on just how darn cool the typesetting was.2
All this may seem harsh on Knuth, but I figure Knuth can take it. He's, well,
Knuth, and I'm nobody. He came up with literate programming as the successor
to structured programming, meaning that he was introducing ordering considerations
at a time when most people were still using gotos as a matter of
course. There was no typesetting for programmers or academics, no internet, no
hyperlinking. No, these early examples are fine for what they are. They
haven't developed because we programmers have failed to develop them
over time. We've been too quick to treat them as sacred cows to be merely
interpreted (not noticing the violence our interpretations do to the original
idea anyway). I speculate that nobody has actually read anybody else's
literate programs in any sort of detail. And so nobody has been truly inspired
to do better. We've been using literate programming, like the vast majority of
us use TAOCP,
as a signalling device to show that we are hip to what's cool. (If you have
spent time reading somebody else's literate programs, I want to hear about
your experiences!)
I've been indirectly maligning typesetting, but it's time to aim squarely at it. There's a fundamental problem with generating a beautifully typeset document for a codebase: it's dead. It can't render inside just about any actual programming environment (editor or IDE) on this planet, and so we can't make changes to it while we work on the codebase. Everybody reads a pdf about a program at most once, when they first encounter it. After that, re-rendering it is a pain, and proof-reading the rendered document, well forget about it. That dooms generated documentation to be an after-thought, forever at risk of falling stale, or at least rendering poorly.
You can't work with it, you can't try to make changes to it to see what happens, and you certainly can't run it interactively. All you can do, literally, is curl up with it in bed. And promptly fall asleep. I mean, who reads code in bed without a keyboard?!
What's the alternative? In the spirit of presenting a target of my own for others to attack, I'll point you at some literate code I wrote last year for a simple interpreter. A sample of what it looks like:
// Programs are run in two stages: // a) _read_ the text of the program into a tree of cells // b) _evaluate_ the tree of cells to yield a result cell* run(istream& in) { cell* result = nil; do { // TEMP and 'update' help recycle cells after we're done with // them. // Gotta pay attention to this all the time; see the 'memory' // layer. TEMP(form, read(in)); update(result, eval(form)); } while (!eof(in)); return result; } cell* run(string s) { stringstream in(s); return run(in); } :(scenarios run) :(scenario examples) # function call; later we'll support a more natural syntax for # arithmetic (+ 1 1) => 2 # assignment (<- x 3) x => 3 # list; deliberately looks just like a function call '(1 2 3) => (1 2 3) # the function (fn) doesn't have to be named ((fn (a b) # parameters (params) (+ a b)) # body 3 4) # arguments (args) that are bound to params inside this call => 7
A previous post describes the format, but we won't need more details for this example. Just note that it is simple plaintext that will open up in your text editor. There is minimal prose, because just the order of presentation does so much heavy lifting. Comments are like code: the less you write, the less there is to go bad. I'm paying the cost of ‘//’ to delineate comments because I haven't gotten around to fixing it, because it's just not that important to clean it up. You can't see it in this sample, but the program at large organizes features in self-contained layers, with later features hooking into the code for earlier ones. Here's a test harness. (With, I can't resist pointing out, the includes at the bottom.) Here's a garbage collector. Here I replace a flat namespace of bindings with dynamic scope. In each case, code is freely intermingled with tests to exercise it (like the scenarios above), tests that can be run from the commandline.
$ build_and_test_until 029 # exercises the core interpreter $ build_and_test_until 030 # exercises dynamic scope ...
Having built the program with just a subset of layers, you're free to poke at it and run what-if experiments. Why did Kartik write this line like so? Make a change, run the tests. Oh, that's why. You can add logging to trace through execution, and you can use a debugger, because you're sitting at your workstation like a reasonable programmer, not curled up in bed.
Eventually I'd like to live in a world where our systems for viewing live,
modifiable, interactive code are as adept at typesetting as our publishing
systems are. But until that day, I'll choose simple markdown-like plain-text
documentation that the author labored over the structure of. Every single
time.
1. Literate Haskell and CoffeeScript to a lesser extent allow very flexible ordering in the language, which mitigates this problem. But then we have their authors telling us that their tools can be used with any language, blithely ignoring the fact that other languages may need better tools. Everybody's selling mechanisms, nobody's inculcating the right policies.
2. We've all had the little endorphin rush of seeing our crappy little papers or assignments magically improved by sprinkling a little typesetting. And we tend to take well-typeset documents more seriously. The flip side to this phenomenon: if it looks done you won't get as much feedback on it.
comments
Comments gratefully appreciated. Please send them to me by any method of your choice and I'll include them here.
I feel literate programming should borrow more from spreadsheets, Matlab, iPython notebook. Create a session, modify earlier steps, change what is rendered in the main view... but have this whole session correspond to something like a single function (i.e. with some arguments set at the top, running multiple inputs at once in different columns).
Code absolutely should be optimised for humans. It must be made first and foremost for people to read. But literary formatting is a bullshit carryover from the era when printing was considered relevant, and it was considered “correct” and “right” to use serif fonts for everything. Times are changing. I want comments in my source, syntax-highlighted and fitting nicely WITH the code. Not some rubbish code-inside-code for external doc generators that would mix monospace with serif for extra eye strain because some geezers don’t quite understand that computers don’t have to be exactly like printed papers. Let the whole thing RIP.
Reading code is not an especially effective or efficient way to understand code. You're tasked to simulate the behavior of a program in your head. Might as well read DNA to predict the structure of a protein to understand how the protein will fold. We can optimize languages to make code a bit more comprehensible. Ultimately, our apps will scale beyond what anyone is even willing to understand through reading.
Beyond toy examples, people don't really read all that much code. Even in open source.
"The average programmers writes 10x more code than they read. The only people where that equation is reversed are professional code auditors" -- Many eyes, Graham
So, if not reading, how should we understand code?
I think: by playing with it. By modifying code and inputs and observing what happens. By having the ability to visualize what is happening - not just at the edges of the software, but internally. See Conal Elliott's "Tangible functional programming" and Bret Victor's "Learnable programming." We need the ability to break things and repair them.
Well, that's part of it. But even play won't scale very well if the interactions are global. Systems will quickly grow bigger than our heads. So, we need some intuitive rules that let us understand which parts of the system might be affected by a change - i.e. locality and inductive properties.
I recently read an interesting article on Mixing Games and Applications. It describes how to make apps interesting to users: "You need to be able to fail and explore the possibility space of a particular tool. Through repeated failure and success, users build up robust skills that can be applied successfully in a wide variety of situations.".
We would benefit from this sort of exploratory learning for our languages, the ability to 'play' with a codebase like a game... and perhaps even offer game-like challenges to help a newcomer to a codebase gain some understanding of it. It seems to me that DVCS systems offer half of this sandbox, limiting the amount of damage users can inflict on a codebase. A candidate for the other half might be capability security, limiting the amount of damage a code base can inflict on the users.
I am pursuing these ideas in Wikilon, a wiki-based IDE and live software platform. Each user of the wiki will have a transactional view of not only the codebase but also the many web-apps and web-services hosted by it. Thusly, users can edit a codebase, observe a live impact on their web applications, yet preserve this as a personal (session) view until they wish to share changes by committing them.
(Many thanks for that quote/link rebutting many-eyeballs.)
To convey ideas to human, I again agree with you that the ordering is the most important element. Human only can comprehend 5 +/-2 items at a time, and we comprehend anything by a shifting window of context. Without a comprehensible order, the context is frequently to large to fit in our working memory and get lost and forces devoted code readers to go back and forth and often engage in an effort of *reconstructing* the context.
For the last couple of years, I have been developing and programming in a meta-layer MyDef. Above all the other features, it allows reordering of most programming languages. You may also interested in some of my blog, e.g. my imperative parser series, which in fact is an example of literate programming.
It reminds me a bit of Leo, the literate text editor. Have you seen that?
I'd love to chat more offline. (My email is at the 'feedback' link up top.)
Sometimes I think we few enlightened souls are each programming in our own private literate-programming setups. So far they're useful for us to write in, but we're lonely voices in the desert when it comes to the rest. Lately I just take this ability for granted and focus on other ways to improve the on-boarding process, either for introducing codebases to programmers, or for introducing programming itself. Hopefully a more full-featured package will be easier to swallow than isolated mechanisms.
I’m responding, somewhat fraudulently (vide infra) and certainly asynchronously, to your request - “If you have spent time reading somebody else’s literate programs, I want to hear about your experiences!” – which (request) you placed within your excellent (and quite liberating) October-2014 Knuth-is-doing-it-all-wrong article. The fraud consists in my having “spent time” that is best measured in minutes – at best, hours – on this Holy-Grail pursuit of expressiveness-cum-precision in programming-cum-documentation. My resulting disappointment and frustration vis-à-vis Literate Programming continue to be disproportionately high with respect to the work I expended in having put the strongest force at my disposal through a vanishing distance, thus effecting negligible work.
Although Professor Knuth sent me a total of $4.56 ($2.56 in 1979, and $2.00 in 1984), and will remain a very big Somebody in my estimation, I too regard myself as occupying the complementary partition. However, it seems to me that, notwithstanding your self-placement, you are in fact (a) Somebody (with whom to contend) who commands software developers’ respect and appreciation – and you certainly have mine, big-time.
Regards and thanks, George Hacken
Interactive literate program development is trivially easy, at least on linux using Emacs and Latex. Open the literate program in a buffer. Start a shell buffer. Now the cycle is:
Do forever: Edit the literate program to change code and/or text Switch to the shell buffer and type 'make'
The makefile 1) extracts the latex (usually called 'tangle' (see below)) 2) runs latex/bibtex/dvipdf/evince to a) remake the document b) pop up the pdf 3) extracts the code ('weave'), compiles it, and runs it.
So on EVERY change you rebuild the document and test the code. The cycle is fast. The code and the text are all in one file. Literate programming allows the code to appear in any order.
Note that Axiom does not need a 'tangle' program because everything is pure latex. So all you need is a program to extract the code (weave).
You can also do this with HTML.
Making LP work is trivial. Changing the way you work is the challenge. If you still create directories of little files (invented because no file could exceed 4k on a PDP in 1970) you are living in the past century.
There's a huge difference between "sat12.w" and "sham.w". One is long, has lots of explanatory prose, and describes things before they are used. The other is brief, has the same structure as an ordinary program, and is practically unreadable.
I wouldn't hold it against Knuth too much that "sham.w" is written as plain-C-in-web. Maybe he never got around to editing it. I've certainly got lots of projects like that.
There's good and bad parts of LP, but it's not fair to pick examples of bad LP and use them to criticize all of LP, even if they were written by the guy who invented it. Some of the Wright planes crashed, but that doesn't mean airplanes are bad.
I would have not written this post as it was if I'd found a single program on Knuth's page of Literate Programming examples that didn't have its #includes at the start. It's a minor issue, but a sign that these programs aren't perfect but should be seen as artifacts to improve upon.
I absolutely think literate programs are a strict improvement on non-literate ones. But why are we not making them continually better? I wish there was a network like that of early bloggers, sharing literate programs, responding to literate programs with new literate programs, improving, integrating style ideas from multiple sources.
That's literally what music notation is for.