Oct 30, 2019
Update on the Mu computer's memory-safe language
I wrote about it last week, but already that post is growing out of date. Here's an initial sketch.
So far all that works is function definitions with no arguments or body. They emit just the prologue and epilogue code sequences.
But I have a sketch of the next few steps of the design in there.
The design has changed in 2 ways.
#1: no more uninitialized variables. There's just no safe way to avoid initialization when structs can contain pointers.
This adds overheads to local variables in two ways: performance, and translator complexity for length-prefixed arrays. We can't just zero out everything, we also have to write array lengths in. Since structs may contain arrays, initializing a variable may involve writing lengths to multiple locations.
#2: unwinding the stack when exiting a scope. I can't just increment the stack pointer, I need to also restore any necessary registers along the way.
Another complication is that I need Java's labeled breaks. Since break does double-duty for both conditionals and loops, it's too onerous to only be able to break out of one scope at a time. But labeled breaks increase the frequency with which I need to unwind the stack. More overhead.
The common theme here seems to be that the translator needs to maintain 'symbolic' representations of contiguous memory regions, tracking either values or register bindings for offsets.
I'm not sure how I feel about these choices. Perhaps I should give up on this whole design and switch to something more traditional. A memory-safe C-like language. So I'd love to hear feedback and suggestions.
Project link
permalink
* *
Oct 25, 2019
Starting to wrestle with the problem of safe, efficient array initialization.
Here's Rust
permalink
* *
Oct 21, 2019
Lots of interesting discussion and feedback about
my "level 1" language over the last few days. Now that it's starting to settle down I'm starting to work on my "level 2" language: type-safe, memory-safe, manually register-allocated, maps mostly 1:1 to machine code.
Since I'm building it out of machine code, memory management is a perennial concern. My parsing in level 1 has mostly used static arrays. But now I think I'm going to switch to dynamic linked lists and trees. Leak some memory.
permalink
* *
Oct 15, 2019
Update on the Mu computer
I just wrote up a summary of the state of Mu, in two parts.
Part 1 summarizes the past year as a sequence of major design decisions:
http://akkartik.name/post/mu-2019-1
Part 2 is a sketch of what I plan to build next, again structured as a sequence of design decisions:
http://akkartik.name/post/mu-2019-2
(The flow from design constraints to decisions is inspired by Christopher Alexander.)
Any and all feedback appreciated. I'd like it to be clear to any programmer.
permalink
* *
Oct 2, 2019
I'm thinking about
https://zge.us.to/dirconf.html
What if cating a directory rendered its contents as a structured file?
First reaction: get rid of directories altogether. But it seems useful to firewall off different kinds of content from each other.
Still, the file system could support treating files as dirs.
It seems useful to have consistent lexical conventions spanning paths and code: '#' for comments; '.' for lookup; '/' for metadata. E.g. to look up gitconfig:
cat ~.conf.git.core.pager
Metadata is a new idea here; I use it extensively in my Mu project. In this context, one possible use for it is extensions. Rewriting the above example:
cat ~.conf.git/yaml.core.pager
Swapping the usual meanings of '/' and '.' in Unix seems maximally confusing. I'm choosing here to preserve the meaning of '.' in source code. But that may be the wrong choice.
Anyways, back to metadata. It permits multiple extensions. Say for a MS Word doc:
thesis/doc/docx/doc-v2007
permalink
* *
Sep 30, 2019
I'm poking at
https://github.com/ozkl/soso trying to figure out where it first switches from Ring 0 to Ring 3. I want to rip out all of that protection stuff and just run everything in Ring 0. Just as an exercise for starters, but also eventually because I have.. notions.
After various attempts to grep, the current plan: I'm going to just try to write to some protected address at various points in the kernel, and binary-search my way to the solution. Let's see how this goes.
https://github.com/akkartik/mu#readme
On the language side I've been thrashing a fair bit:
- Between the OS side vs the language side.
- Between building an interpreted, dynamically-typed language in machine code vs a compiled, statically-typed memory-safe language that I can build the interpreted language out of.
- Between building a Lisp interpreter vs a better shell (in the spirit of Oil shell).
- Between making local vars in the compiled language function-scoped vs block-scoped.
permalink
* *
Sep 20, 2019
Update on the Mu computer
We now have structured control flow (with goto statements 😂 )
Compare this screenshot with the ones in the previous message of this thread.
At this point I think I've climbed as far up the ladder of abstractions as I can with just syntax sugar. The next step up will be a new language. It'll still look the same: registers, curly braces, one operation to a line. But operations won't be x86 opcodes anymore. Registers and operands will have types.
permalink
* *
Sep 14, 2019
Update on the Mu computer
A few days ago I found out about a hobbyist OS called Soso.
Today I've gotten Mu running on it well enough to make it a first-class supported platform alongside Linux.
https://github.com/akkartik/mu#readme
LoC of C I depend on thus goes down from 12M to 33k.
It's not a complete replacement, though. I still plan to work with Linux, particularly for its networking support. But it's so cool to have a minimal stack supporting graphics!
permalink
* *
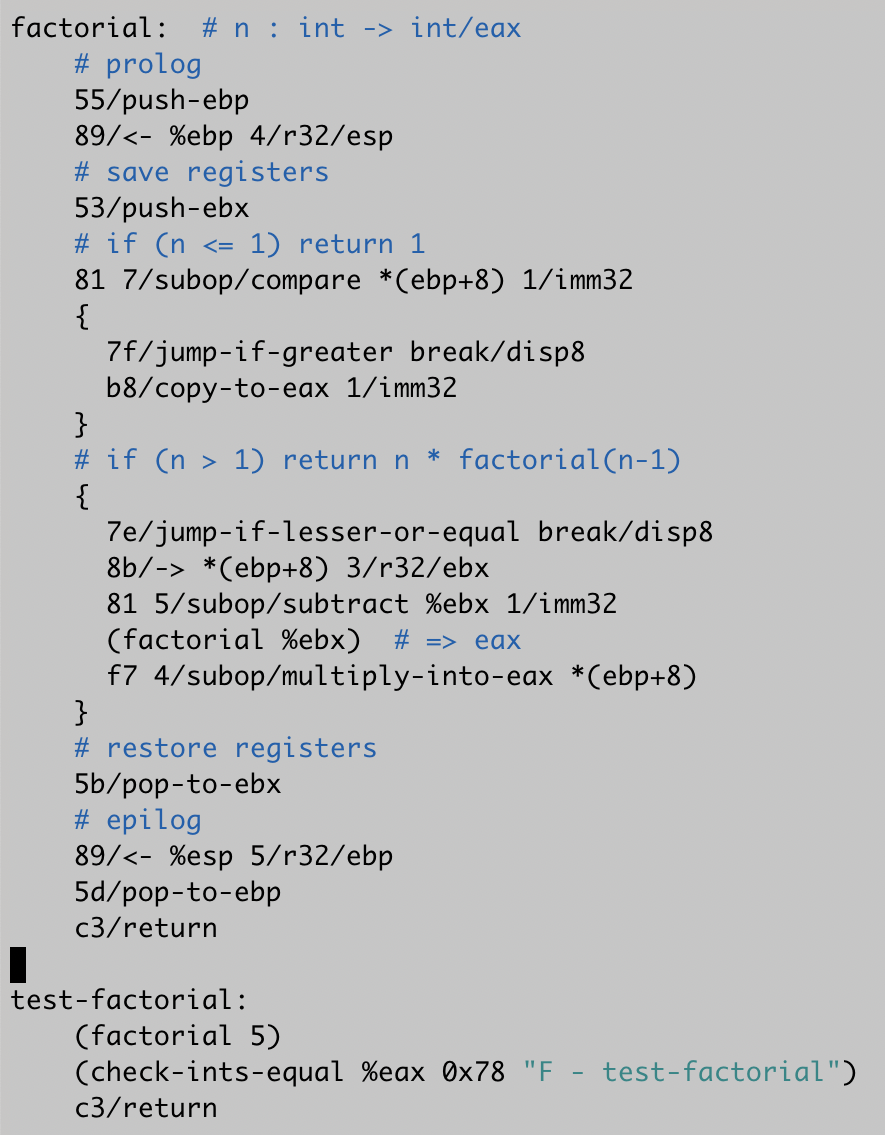
Sep 6, 2019
Update on the Mu computer
Syntax sugar for function calls is done. Here's factorial with no sugar, addressing modes and function calls, respectively.



Time now to start building a proper language, to occupy C's niche on this new stack. Type-safe, memory-safe, manual (but safe) memory management, manual (but safe) register allocation.
Though I might build a toy Lisp first. I figure I've earned some fun. Seeing a computer boot into a REPL would qualify.
https://github.com/akkartik/mu#readme
permalink
* *
Sep 3, 2019
How SubX code has evolved over the past year
2018/Jul/30
2019/Sep/03
The first thing that pops out is that lines have gotten narrower.
Or have they? Scroll down and some long lines start to show up. Even if you ignore trailing comments. Check out the screenshot. Lines wider than 80 characters translate to 2-byte jump instructions. I wonder if I've lost my sense of proportion somewhere along the way.

permalink
* *